Как улучшить онлайн-репутацию с помощью Serpstat
- Евгений Василенко, Serpstat
-
•
-
18:00, 11 ноября, 2020

Сталкивались ли вы с понятием черный PR. Конечно же, да! Но сегодня вы многое узнаете о том, что включает в себя работа по его обезвреживанию. В этой статье я подробно расскажу о нашем подходе и разложу весь процесс работы над онлайн-репутацией по полочкам. Будет интересно, вперед!
О проекте
Итак. Немного о нас. Я возглавляю команду специалистов в онлайн-репутации. У нас нет названия, у нас нет сайта, у нас нет социальных сетей. Все, что можно найти о нас — это только мои личные социальные страницы и моя история 12-ти летнего опыта в маркетинге, SEO, SMM, SERM, ORM, OSINT и PR.
OSINT — это использование возможностей открытых источников информации, доступных в интернете, на максимальную мощность. Различие между простым поиском в сети и OSINT'ом в глубине подхода — нельзя изучить рацион глубоководных рыб, наблюдая за рябью на поверхности океана.
У нас нет опубликованных кейсов, так как большая часть наших клиентов — люди публичные, и мы работаем строго по NDA. Никто из наших клиентов не знает, с кем мы работаем сейчас, и с кем работали ранее. Наша команда хорошо разбирается в алгоритмах работы сетей, сайтов, роботов, поисковых систем.
Из чего состоит работа
Самая интересная часть нашей работы — это сбор информации. Это огромный объем работы, связанной с ручным и автоматическим сбором данных, которые касаются того или иного человека, компании, бренда или товара. Чаще всего мы работаем с личностью, реже с компаниями и брендами. Поэтому мы отлично понимаем что такое личный бренд в реалиях сегодняшнего социума.
Мое последнее высшее образование я получал в Академии Госуправления на кафедре информационной политики (связи с общественностью), и моя курсовая работа и часть диплома была на тему «Информационные войны». Поэтому мой опыт в маркетинге дополняется пониманием информационных войн и управления массами. Для сбора информации используем большой список источников. Количество источников информации чаще всего в проектах не ограничено.
По возможности используем все категории:
- Обычные сайты (новостные, бизнеса или блоги).
- Социальные сети (как минимум работаем с 9 основными и 10−15 дополнительными).
- Обрабатываем такой важный коммуникационный канал, как Телеграм.
- Сканируем Скайп (хотя с каждым годом все реже и реже).
- Плотно работаем с Википедиями всех типов — от настоящей оригинальной до локальных, частных и копий.
- Мы сканируем фото как в онлайн, так и специальными программами для выявления подделки.
- Внимательно изучаем видеоконтент на всех известных площадках.
- Копаемся в истории, умеем изучать технические сети.
Используем для этого немалый список платных и бесплатных сервисов, ведем свою базу данных через различные API.
Глубина поиска всегда непредсказуема. Так как, найдя определенный контент, мы можем углубиться в найденное, а потом в найденном углубится еще дальше. Помните фильм «Начало»? Там, где главные герои вводили человека в сон, потом во сне вводили еще в один сон, а в финале фильма они смогли перейти и на 3-й уровень сна. Вот примерно так же в работе с репутацией, когда необходимо через OSINT находить следы черного PR, и создавать способы борьбы с ним.
Возьмем, к примеру, один из наших кейсов. Назовем его «Тарас Тарасович». И вот Тарас Тарасович (далее ТТ) обращается к нам с просьбой помочь с репутацией. При первом срезе мы находим огромное количество контента с черным оттенком, направленного на очернение репутации в сети. Примерно 95% всей информации о ТТ — негативная.
Информации много и разной, на разных каналах и в разное время написанная. Мы также сразу понимаем, что создана целая PR-кампания, кем-то финансируемая и с конкретными целями на результат.
Наша задача — изменить 95% негативной выдачи на 95% позитивной, или, в худшем случае, — на нейтральную. В первом блоке работы, напомню, у нас сбор информации. То есть мы начинаем искать (всеми возможными способами) любое упоминание на 3-х языках (русский, украинский, английский) о человеке ТТ. В результате появляется файл с огромным количеством ссылок на тот или иной контент, где есть упоминание.
Все результаты мы разбиваем по категориям — сайт, соц. сеть, блог, видео и т.д. Ставим возле каждой ссылки оттенок негатива по пятибалльной шкале. К примеру, если в заголовке H1 и/или тайтл есть наш ТТ — то это максимальный балл — 5. Если заголовок не о нем, но в тексте упоминается ТТ 1−2 раза косвенно и без разметки — это 1-2 балла. Если ФИО ТТ выделен жирным, проставлен тег или анкор — это 3−4.
Способы составления этого файла постоянно меняются, добавляем новые критерии, новые функции и оттенки. Технологии не стоят на месте, поэтому каждый проект получает все последние инсайты и технологии, внедренные на предыдущих проектах.
Следующий этап — это найти связи между всеми публикациями. Представьте, что у вас есть 100 ссылок (хотя их бывает намного больше).
Анализ сайта
Пусть это будет 80 источников (часто на 1 сайте могут быть 1−2 статьи). И ваша задача найти между ними связь. Вот здесь нам и нужен Serpstat (я использую сервис уже 4-й год).
Что у нас есть на старте:
- список ссылок
- список сайтов
- список анкоров
- список внутренних ссылок в найденных статьях
- список ключевых слов, по которым гуглится контент, связанный с ТТ
- и так далее.
Из всех ссылок составляю список с наибольшим «весом». Критерии определения веса:
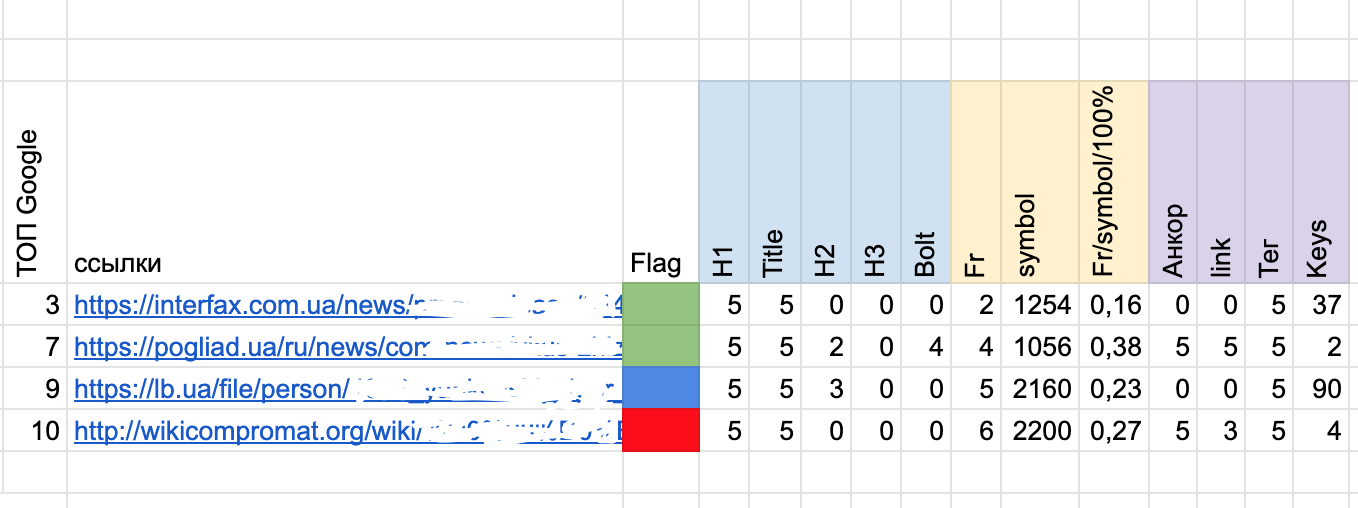
1. Нахожу ключевые слова, по которым гуглится данная страница (одна из 100).
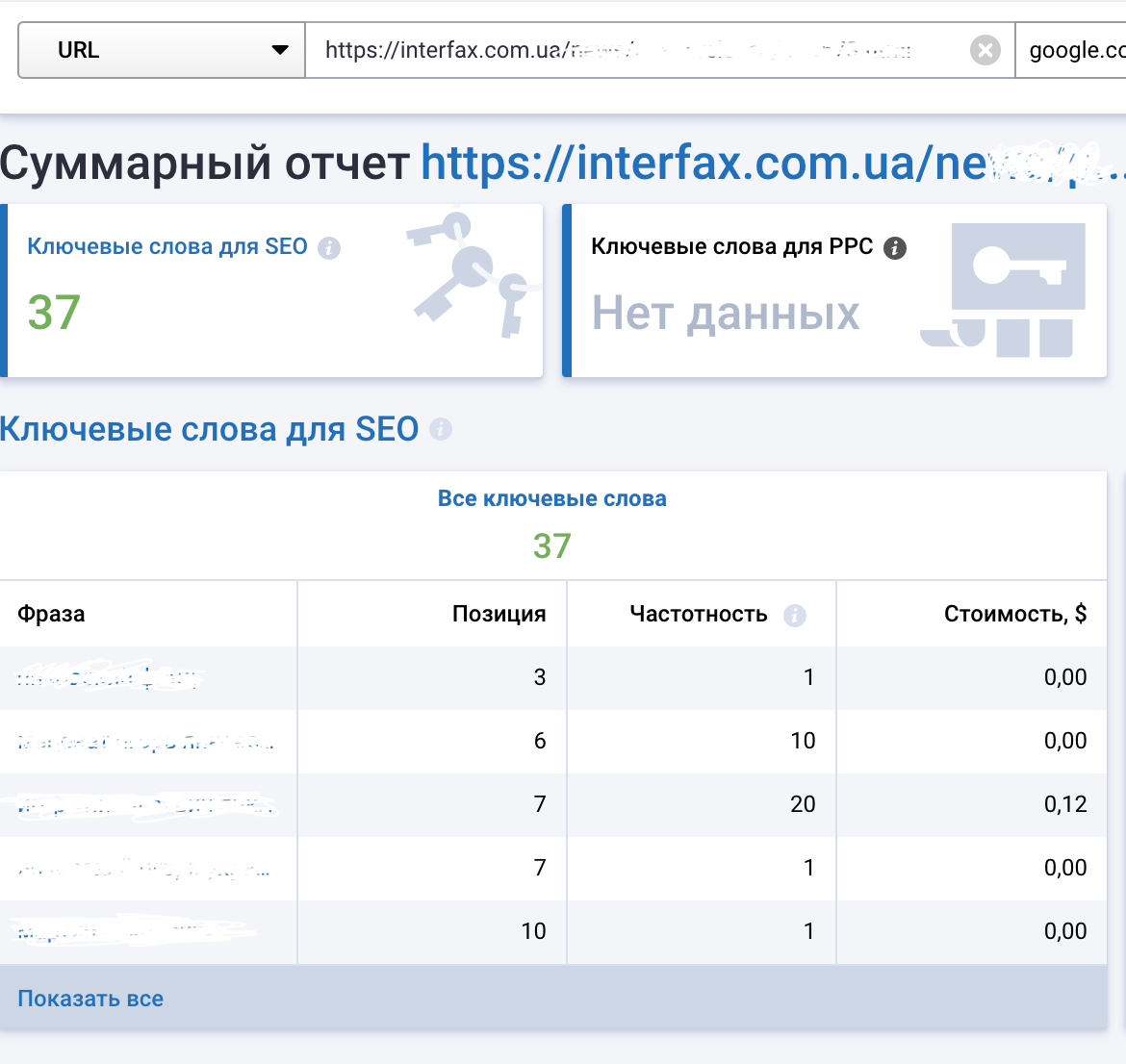
2. Проверяю конкурентов конкретно для этой страницы по конкретным ключевым словам.
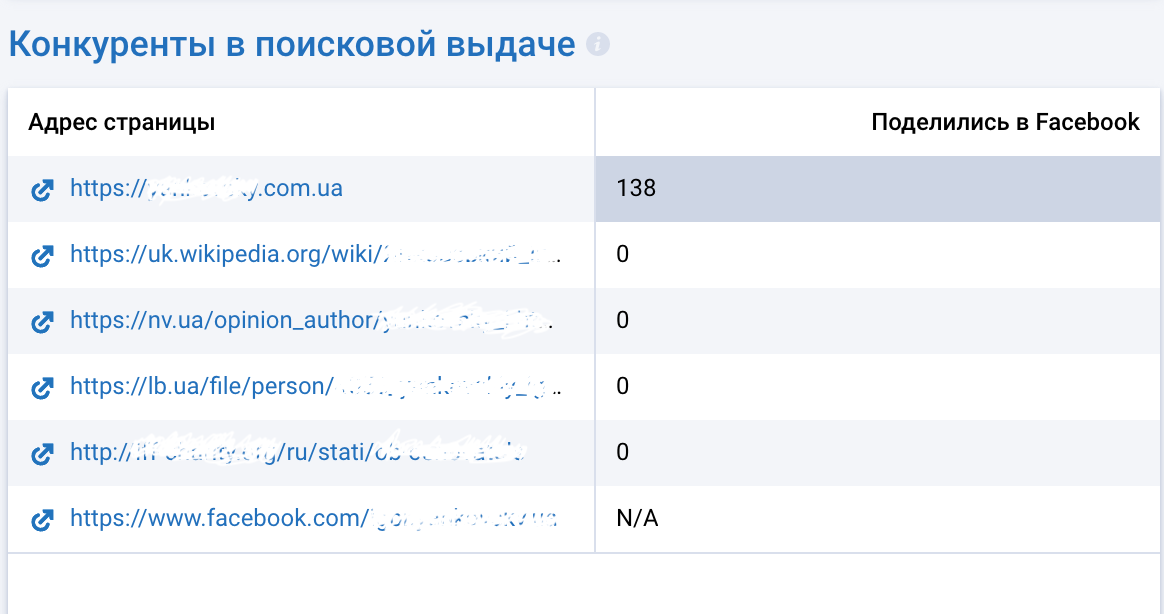
3. Пишу список в отдельный файл. А также количество ключевых слов и их meta в выдаче. Проверяю и сопоставляю мои целевые ключи (в данном случае подобранные по ФИО нашего проекта ТТ). Все записываю в рабочую таблицу.
4. Нахожу через Serpstat внешние сайты, которые ссылаются на данную статью — обязательно проверяю анкор на внешнем сайте, так как, если анкор имеет мой ключ, то это очень важная находка.
Здесь нужно понимать, что, если у нас есть статья с черным PR, в статье есть наш ключ — ФИО ТТ, и мы находим внешний сайт, который ссылается на эту статью с нашим анкором, то это явный признак «промо» данного контента с целью поднятия в поиске.
Такие сайты сразу уходят в мой топ-10 по этому проекту. Но здесь важно не упустить и другие уровни, и копнуть еще дальше — на 3-й уровень. Ведь моя задача не найти все ссылки, а выявить закономерность в их появлении, хронологии, ключевых словах.
Если работают профи в черном PR, то они это делают системно, по четкому плану. И чем быстрее я выясню этот план (хотя бы его гипотезы), тем быстрее я сформирую защиту и противодействие.
Уточнение:
1-й уровень — наш первый сайт с контентом и упоминанием.
2-й уровень — это чаще всего нишевый (сателлит или один из доменов «группы сайтов», который ссылается на 1-й.
Моя задача — копать дальше. Искать и, возможно, найти следующие уровни 3-й, 4-й и так далее.
В этом случае чем больше глубина, тем ближе этот сайт к 1-му месту в моей таблице топ-10 проекта ТТ.
За 1 день в Serpstat бывает я могу проверить 50−100 страниц, не сайтов, а конкретных страниц, где есть упоминание, а также проверить ссылки, которые ведут на эти страницы.
Анализ контента
Второй инструмент, который мне нужен в Serpstat — это ключевые слова и контент. На первом этапе мы всегда уточняем дату публикации, время публикации и возможные апдейты контента.
В отдельном списке записываем сайты в хронологическом порядке. Таким образом, находим сайты, на которых были самые первые публикации по времени. Берем оттуда ключевые словосочетания (иногда целые предложения) и гуглим на их повтор. Находим сайты, которые перепечатали часть или полный текст — и записываем их в рабочую таблицу. Далее все эти сайты снова идут в Serpstat для анализа.
Также с помощью инструмента с контентом изучаем количество вхождений H1/H2/H3 и составляем гипотезу, которая нам дает понимание причин попадания именно этой страницы в топ-10 выдачу в Google. Ведь, напомню, у нас задача — убрать 95% негатива.
При этом личного сайта или блога у ТТ нет, у него есть только пару аккаунтов в социальных сетях. А нам надо бороться с целыми новостными сайтами с миллионным трафиком. Поэтому уже через месяц работы мы запустили сайт с нуля — как личный блог нашего ТТ. После анализа всех 100 найденных страниц 1-го уровня у нас с помощью Serpstat будет:
- количество вхождений по ключам;
- топ выдача по этим же ключам;
- количество ссылающихся страниц/сайтов на сайты 1-го уровня и их список;
- количество и список сайтов 2-го уровня и на кого они ссылаются;
- количество и список 3-го уровня и на кого они ссылаются;
- анализ контента, где мы возле каждого сайта видим количество H1/H2/H3, жирный текст, теги, внутренняя перелинковка и так далее;
- кол-во сайтов, где ключ находится в тайтл, а также обработанный, первой итерации список топ-10 сайтов с максимальным весом.
Далее мы анализируем медиа-контент — в нашем случае фото ТТ. Находим их в Google картинках и проверяем в Serpstat влияние спецэлементов, ищем совпадение фото/видео с нашим целевым контентом.
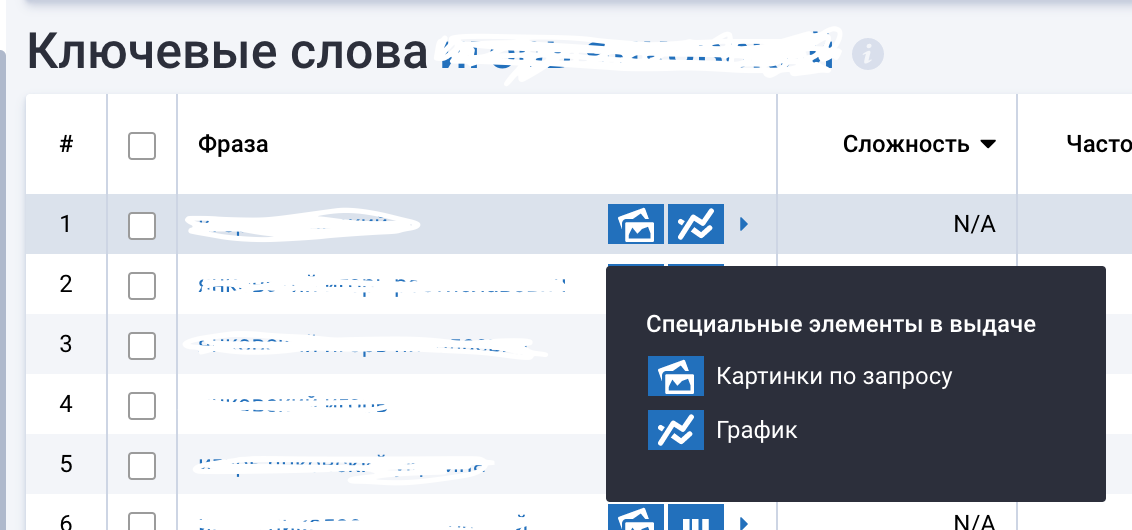
Проверяем влияние спецэлементов на выдачу. Здесь надо учитывать и то, что при работе с репутацией человека, в особенности в работе с черным PR, чаще всего используется медиа-контент, который доступен в индексе. А значит — одну и ту же фотофрафию могут использовать разные источники, дописывая к нему разные Alt и текст. Иногда в сниппете можно найти изображение, что существенно добавляет работы для нас в будущем.
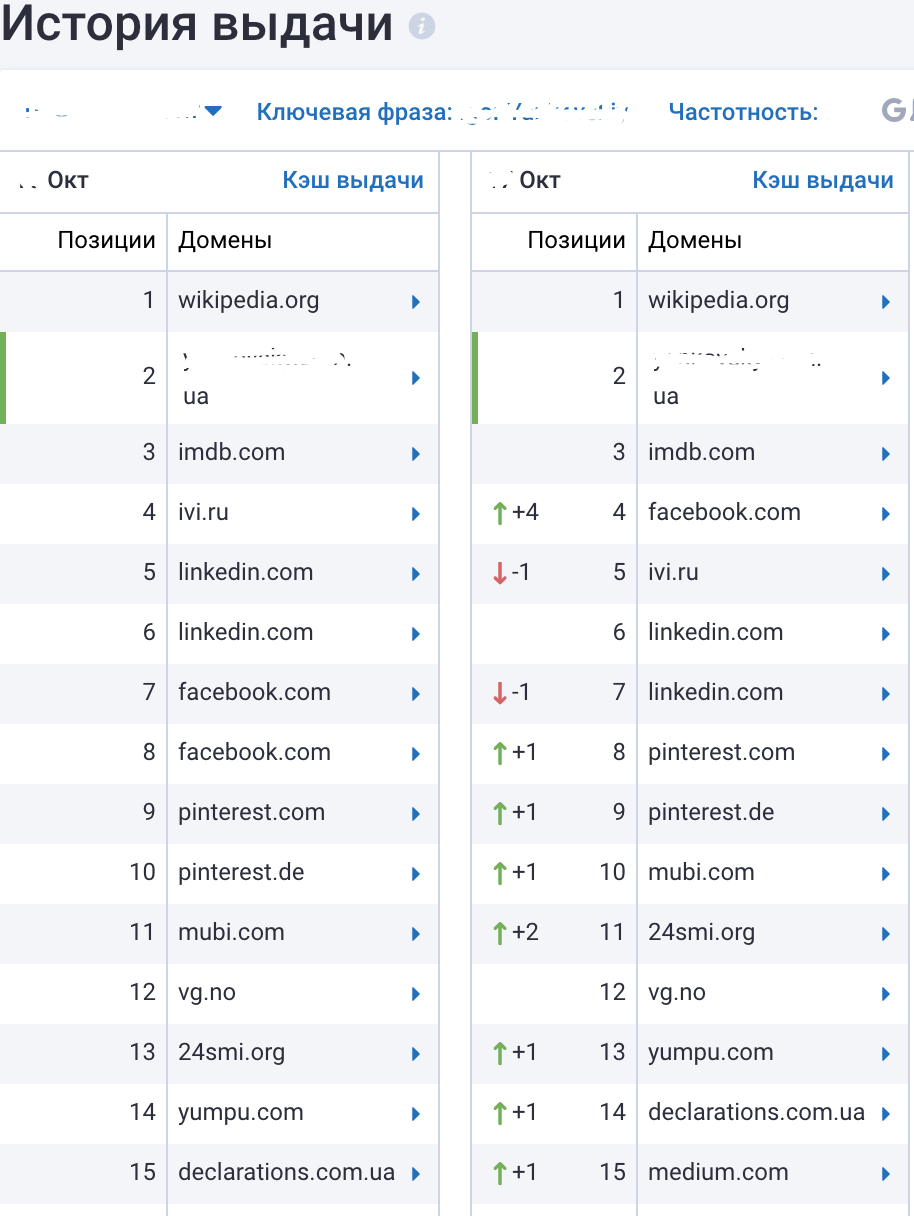
Не забываем проверить и социальные домены при анализе по ключевой фразе. Так как наличие в конце таблицы иконки Wikipedia дает нам сигнал к действию:
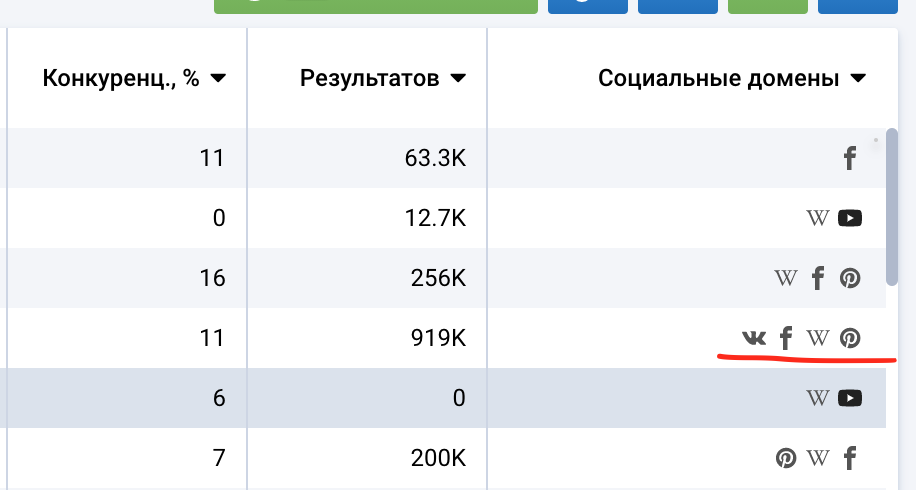
В работе с репутацией такие сайты как Wikipedia, Youtube и часто забываемый Pinterest дает ощутимый результат и вес в борьбе против Черного PR. Это отдельный блок работы, о нем не здесь и не сегодня.
Также анализируем конкурентов по основной ключевой фразе:
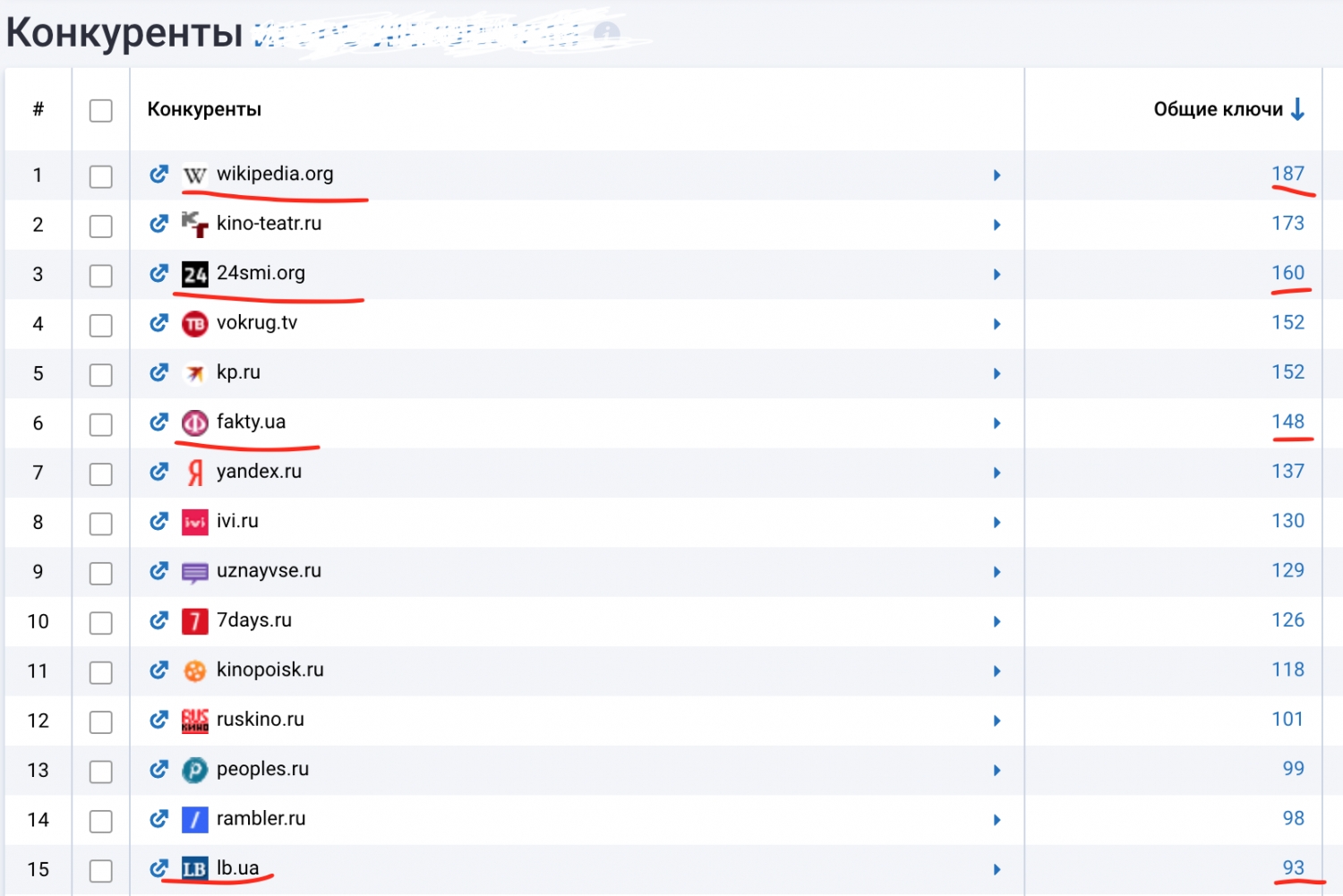
Нажимая на общие ключевые слова по новостному ресурсу, я могу найти все слова, по которым данный ресурс видим для Google.
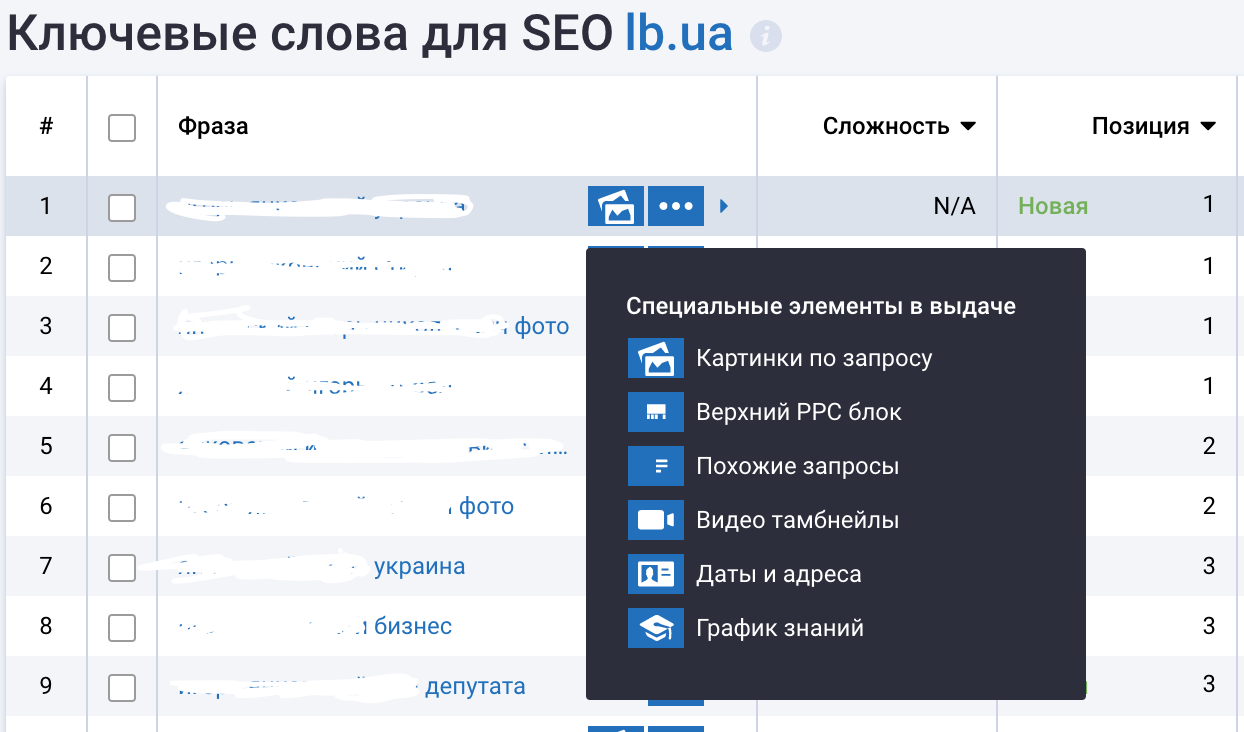
В самом конце этой таблицы есть сам URL (страница), который и занимает место в топе по моему ключу. Поэтому идем еще глубже:
Перейдя на следующий анализ данной страницы — получаем полный анализ этой отдельной страницы, где мы сможем найти (конкретно по странице, а не по целому сайту):
- количество ключевых слов в топе для этой страницы;
- конкурентов по поисковой выдаче (это важно знать) — с какими страницами еще конкурирует отдельная страница.
И в этой таблице я уже сразу нахожу страницу с негативным оттенком:
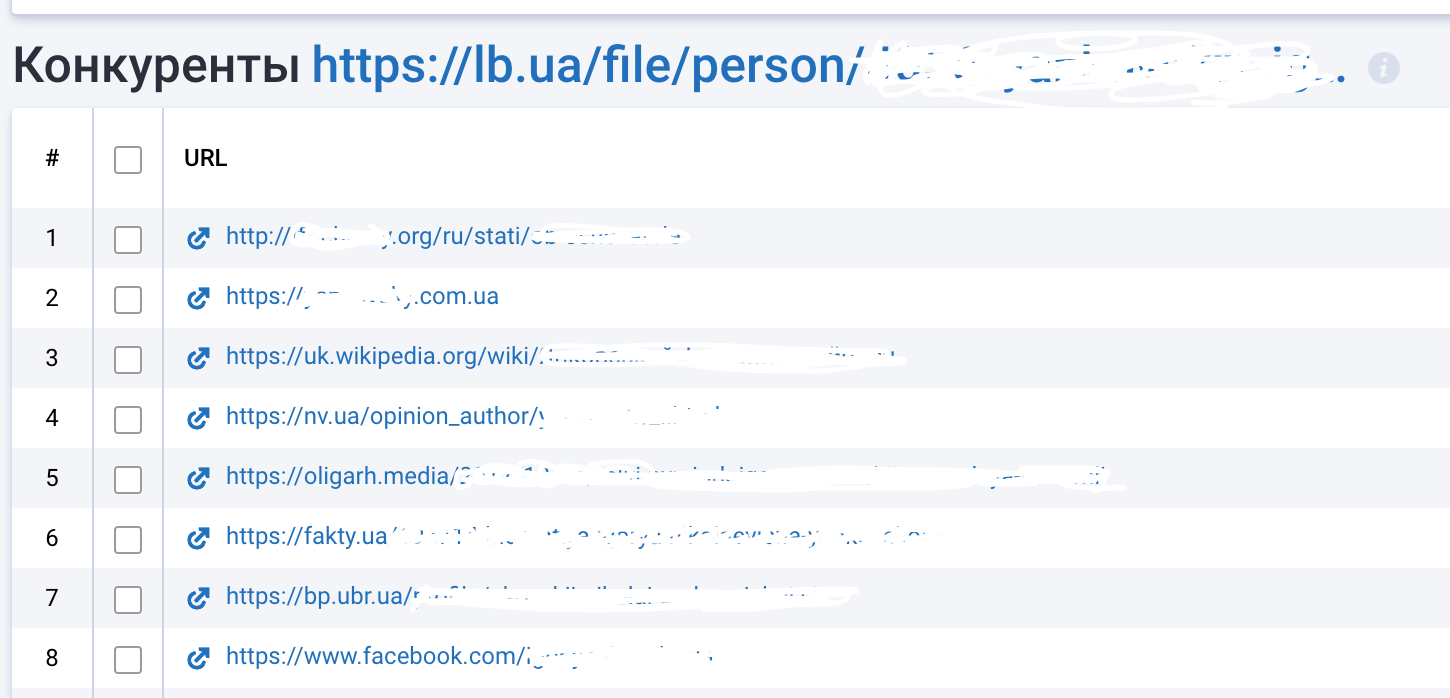
Анализ ссылочных доноров
Ну и последний инструмент Serpstat, который только недавно вышел — это Пересечение доноров.
Что делаю здесь:
Так как черный PR часто разгоняется по очень мелким а-ля новостным ресурсам (есть целые списки из сотен новостных сайтов/агрегаторов, через которые «пушатся» те или иные «новости». В этом случае моя задача определить этот пул (список) сайтов, через которые разгонялась новость негатива, записать их в отдельную таблицу и прогнать через Serpstat по пересечению доноров пачками по 3 сайта.
Так я вычисляю сайты, которые между собой делают перелинковку и репосты одинакового контента.
Параллельно с этапом поиска негатива, перед подготовкой стратегии противодействия, мы формируем и белый список сайтов — там, где у нас позитивная или нейтральная оценка контента.
Мы также заносим все найденные «белые» страницы в мониторинг Serpstat, оцениваем их вес, уточняем места в выдаче и конкурентность по сравнению с черной выдачей.
И поэтому главное отличие SEO-работы от работы в SERM/PR/OSINT — это работа не с 1 сайтом для продвижения, а с каждой неделей все нарастающим количеством сайтов, которые нужно «продвигать» теми или иными способами.
Ведь если у нас 100 сайтов на старте с негативным оттенком и 5 с позитивным, значит, нам надо 5 сайтов не только сопровождать и наблюдать, но и придумать способы их продвижения, не имея при этом доступов к изменениям на сайте и изменению контента.
Через 2−3 месяца, если мы все делаем правильно, у нас может быть уже 10 сайтов с белым оттенком, которые нужно также как-то двигать в противовес с черным. Вот такая интересная работа:)
Составление плана противодействия
Проекты по репутации — это проекты не на 1−2 месяца. Они могут длиться и год и более. И соответственно, за это время мы можем создать сайт для ТТ (блог) — его личный и публиковать контент с учетом наших «находок» и рекомендаций из рабочих таблиц. При этом новый сайт мы добавляем в наблюдение в Serpstat и смотрим нашу работу в действии.
Чаще всего при работе с репутацией, нам приходится добавлять в проекты несколько десятков новостных ресурсов, чтобы отслеживать динамику показателей по нашим ключам. Каждый новостной ресурс может иметь сотни тысяч страниц и 2−5 млн ключевых слов, среди которых есть наши 10−20 шт., по которым мы устанавливаем наблюдение.
Теперь о результатах
Мы используем не только Serpstat, у нас в активе 9 сервисов, которые помогают в работе с репутацией. По необходимости, используем именно те, которые нам нужны в той или иной ситуации. Но именно Serpstat дает быструю оперативную информацию и оценку отдельных страниц.
Проекты длятся долго, в случае ТТ первые результаты были уже (или только) через 3 месяца. Правда, половина результатов оказались временными, но это проделки алгоритмов)). На этапе создания кампании противодействия мы создали с нуля сайт — личный блог нашего ТТ и его наполняли контентом, каждый из которого должен был противодействовать негативным статьям в сети. На скриншоте ниже результат работы с этим сайтом, созданным с нуля.
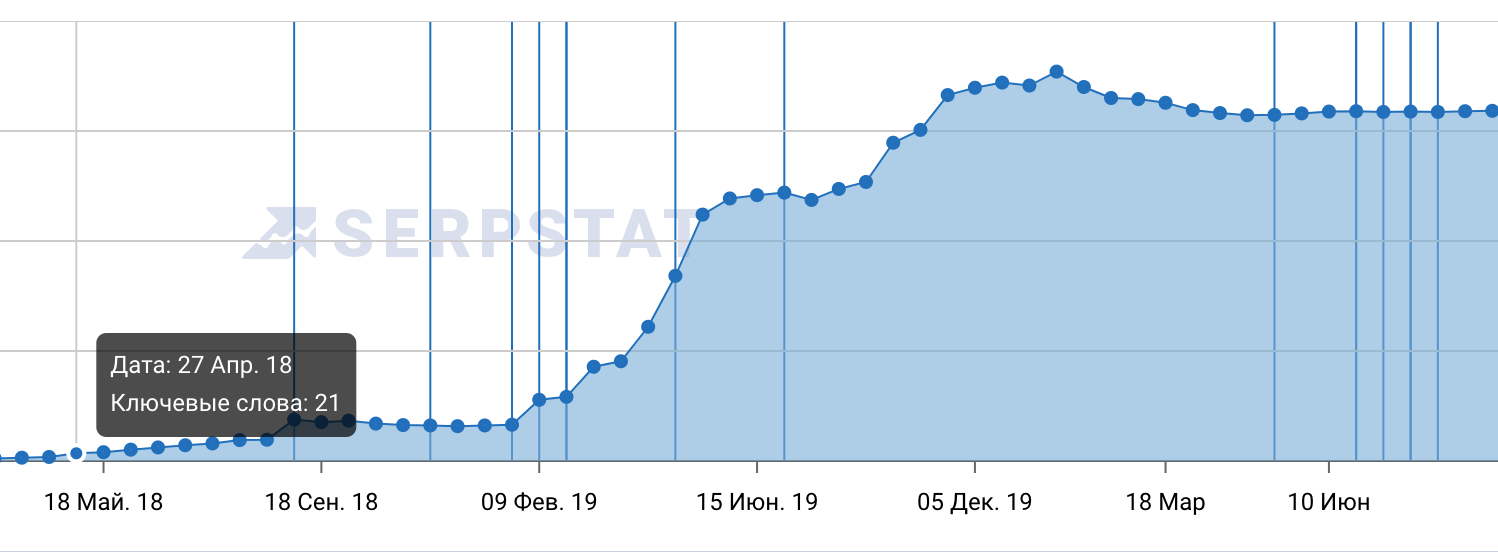
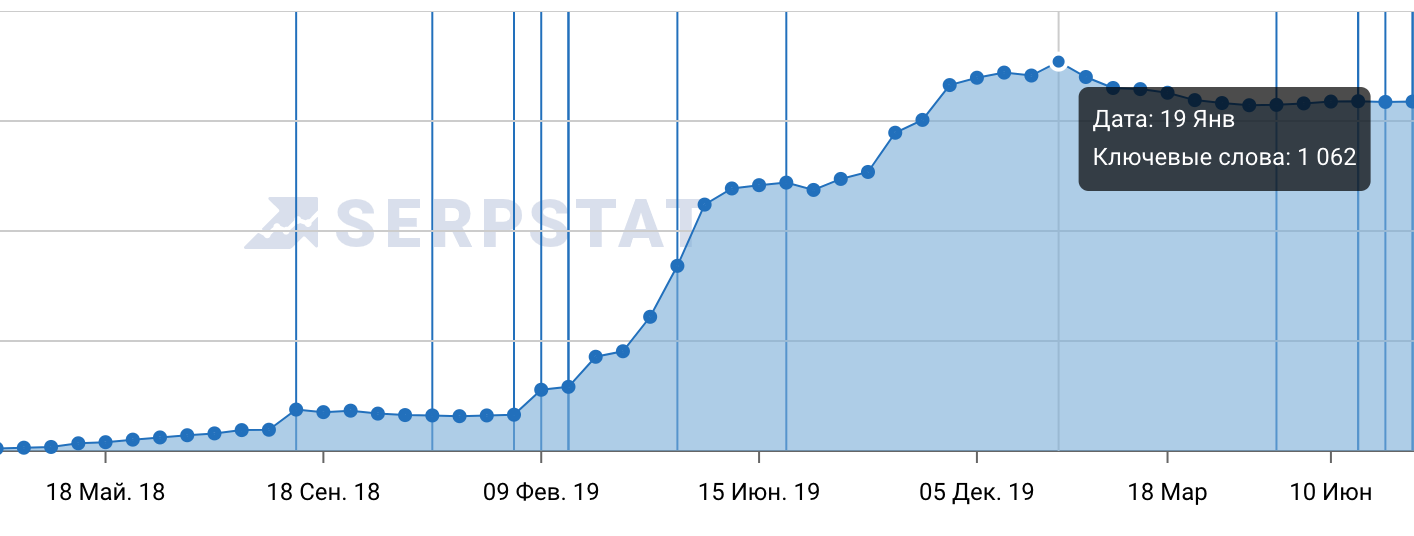
С 5 ключевых слов мы вышли на 1060. В работе с репутациями нет большого количества ключевых слов, но есть огромная конкуренция с новостными ресурсами, где можно за деньги купить/заказать любой контент. Возрастающая синусоида в результатах стала для нас сегодня уже нормой.
Так вот результата в 95% позитива мы достигли только через 1,5 года. На протяжение которых у нас постоянно появлялся новый негатив, на который нам нужно было сразу реагировать и принимать меры, поэтому выходных у нас нет :)Результат крепкий и надежный, как стена на страже репутации. И на сегодня, чтобы попасть в топ-10 выдачи по ключу с негативом для ТТ будет очень сложно, так как путем 1,5 годичного ежедневного анализа, мы вывели в топ самые твердые страницы и усилили их различными способами.
Работая со ссылочной массой на наш основной домен (личный блог ТТ) — это было похоже на гонку на опережение :)
Как только мы получали сигнал о том, что появился негатив в сети, мы изучали страницу — сразу прописывали, какие анкоры использовали «черные ПиАрщики», в тот же день выкатывали статью на основном сайте, где использовали все способы разметки, а также размещали на сторонних площадках свежие, написанные час назад статьи с учетом обнаруженного анкора на негативной статье.
Размещение на других площадках всегда длилось чуть дольше, так как нужно было согласовывать размещение и ждать проверки вебмастеров. Самое важное в этом — быстрая реакция, быстрый ответ и «вес» размещенных нами статей должен быть всегда больше, чем размещенный в негативной статье. Для этого мы проводили анализ и сайта и статьи, ставили наблюдение на появление ссылочной массы на эту новую статью, дабы понять уровень «разгона».
Если мы находили медиа-контент (фото) в негативных статьях — то создавали в противовес свои фото со ссылками, предварительно изучив Alt картинок и текст около картинок.
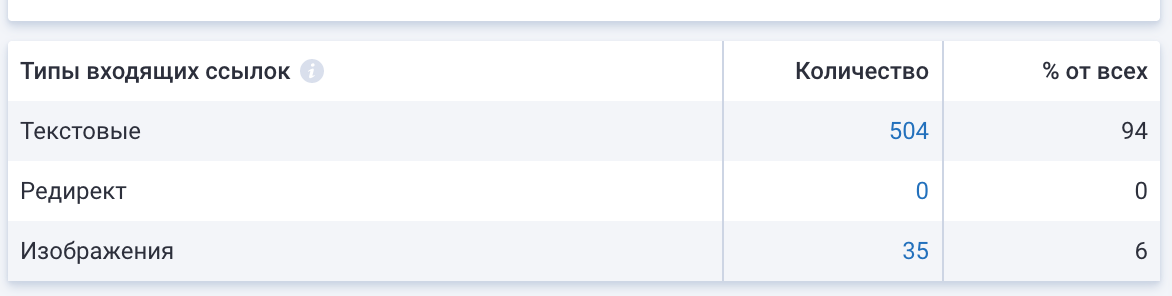
Одна из рутинных работ — это постоянное наблюдение за новостными ресурсами, где уже размещены статьи, которые находятся по нашим ключам. В некоторых проектах таких новостных и около них сайтов было несколько десятков.
Вот представьте себе — добавить в Serpstat 20 новостных ресурсов (на некоторых из них 2−5 млн ключей), прописать под каждый из проектов (сайтов) наши ключи и мониторить после каждого апдейта места в выдаче. При этом не забывать мониторить ссылки на эти статьи, упоминания в соц. сетях и блогах. И, если мы видели рост того или иного ключа (с негативным оттенком) — то мы сразу углублялись в технический анализ этой статьи, изучали причины роста и создавали противодействие в виде нашего контента, наших статей и усиления уже опубликованных статей с позитивным оттенком.
Это кропотливая работа, но она себя окупает во всех случаях, особенно, если человек публичный и от его репутации зависит успешность его бизнесов и проектов и доверия партнеров.
Евгений Василенко, Serpstat